在剛剛過去的2021年,全球發(fā)生的科技變革有:
中國建成全球最大5G網絡,5G基站達70萬個,占全球比重近七成,連接超過1.8億個終端。
MIT(麻省理工學院)與合作團隊僅用19個類腦神經元就實現(xiàn)了控制自動駕駛汽車,而常規(guī)的深度神經網絡需要數(shù)百萬個神經元。
中國“祝融”號和美國“毅力”號火星車分別在火星成功著陸,它們將尋找火星上可能存在過的生命跡象。
2020年全球電動汽車銷量較2019年上漲39%,達到310萬輛。蘋果、百度、小米等互聯(lián)網科技公司紛紛加入造車新勢力,車輛自動駕駛由單車智能邁向車路協(xié)同。
迄今為止,SpaceX已為Starlink發(fā)射了1000多顆衛(wèi)星,預計到2021年年底,Starlink的服務將會覆蓋全球大多數(shù)客戶,并有望在2022年完全覆蓋全球。
上面這些事件只是近期大大小小科技事件中很小一部分,而它們中絕大多數(shù)都涉及大數(shù)據(jù)、人工智能、物聯(lián)網等新興技術。這些新技術通過無數(shù)軟硬件實現(xiàn)萬物互聯(lián),背后離不開智能運維的輔助。
智能運維顧名思義是智能+運維。智能運維的概念是全球知名的IT研究與顧問咨詢公司GART-ner在2016年提出的。當初提出時的英文全稱為AlgorithmicITOperations,意指基于算法的IT運維。隨著人工智能技術的發(fā)展,近兩年該英文全稱逐漸演化為ArtificialIntelligenceforIToperations,突出了人工智能算法在IT運維中的應用,現(xiàn)在,這兩種英文全稱都能在不同文檔中見到,同時并存。
1
智能運維發(fā)展的三個階段
在綜合各方觀點的基礎上,筆者認為智能運維的發(fā)展分3個大階段6個小階段。分別是人工運維、自動化運維、智能運維3大階段。其智能等級參考TMForum自動駕駛網絡從L0-L5逐級遞增,如圖1所示。
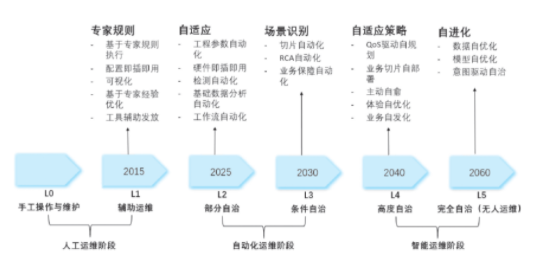
圖1.運維發(fā)展各階段示意圖(以電信運營商為例)
1.人工運維階段
該階段分L0手工操作與維護、L1輔助運維兩個小階段。該階段完全或大部分依靠運維專家的經驗規(guī)則進行故障定位、根因分析和配置下發(fā)等管理任務的制定和執(zhí)行。進入輔助運維的階段,通過對重復性典型事件預先在系統(tǒng)中配置觸發(fā)和調度策略,達到提高運維效率和減少人力成本的作用。
2.自動化運維階段
該階段分L2部分自治、L3條件自治兩個小階段。在L2部分自治小階段,業(yè)內提出了ITIL(InformationTechnologyInfrastructureLibrary)、Devops等理念,強調流程管理質量和打破開發(fā)、運維的邊界。在這個階段業(yè)內逐漸達成IT研發(fā)和運維一體化的共識,但仍未規(guī)模化使用Devops工具,主要依靠在系統(tǒng)中定制編寫自動化腳本,實現(xiàn)簡單數(shù)據(jù)分析、可視化、參數(shù)配置等初始功能,類似早期BI(商業(yè)智能)系統(tǒng)。到L3條件自治小階段,企業(yè)已經認可自動化運維的價值,開始停止自己開發(fā)腳本,轉而使用市場上開源和付費的Devops工具。從OpenStack時代,再到現(xiàn)在的容器時代,借用工具出現(xiàn)了很多自動化運維的高級模式,如網絡可用性工程SRE(SiteReliabilityEngi-neer)、聊天機器人ChatOps等。前者是在保證用戶滿意度的前提下,平衡系統(tǒng)功能、服務及性能多方因素,是涵蓋Devops運維思想、組織架構和具體實踐的完整體系?后者通過插件或腳本實時執(zhí)行團隊成員在會話中輸入的每一行命令,將過去成員在各工具輸入的命令前端化、透明化,以進一步提升自動化程度。
3.智能運維階段
該階段分L4高度自治(又稱智能運維前期階段)和L5完全自治(即無人運維階段)兩個階段。當在某個領域自動化程度達到一定極限時,必然會被人們個性化需求推動著往智能化方向發(fā)展。
L3和L4兩個階段從功能定義上來看,兩者必定會在長期共存的狀態(tài)下進一步演化,預估會共存10-15年,即在此期間內自動化和智能化程度均會逐漸提高。在智能運維早期,AI從單點應用著手,如KPI單指標的異常檢測和趨勢預測,逐步實現(xiàn)在單點應用上的自主發(fā)現(xiàn)問題、診斷問題、解決問題和性能優(yōu)化。并在各垂直領域中,將專家經驗積累成知識庫,形成可重復利用的結構化知識點。
在各單點應用逐漸智能化的前提下,將底層各維度數(shù)據(jù)打通,建立中間通用和專用能力層,靈活應用于上層服務。在每個應用中都能實現(xiàn)從數(shù)據(jù)自主采集、自主預處理到自優(yōu)化,模型上實現(xiàn)自主選擇、調參、優(yōu)化及部署。人們的需求將通過語音、姿態(tài)、神情等特征進行控制和調度,系統(tǒng)也會自主發(fā)現(xiàn)、診斷和優(yōu)化問題。
在時間維度上,由于各行業(yè)自動化和智能化發(fā)展速度參差不齊,即使自動化運維和Devops概念已提出多年,但自動化運維工具在企業(yè)中的使用依然普及率不高,預計到2030年超過50%企業(yè)會普及使用Devops工具。同理,即使從2016年開始,已有企業(yè)開始嘗試在單點應用上借用AI技術,但要大多數(shù)企業(yè)能達到高度自治的水平,依然至少需要20-30年時間的探索和發(fā)展。而要實現(xiàn)無人運維需要研發(fā)和搭建以算力網絡、數(shù)字孿生、千腦感知網絡、邊緣智能等技術為基礎的“運維大腦”,在高度自治的智能運維階段基礎上,至少還需要20-40年時間。
隨著人工智能技術的不斷深入,運維管理中,人的角色越來越主動,對數(shù)據(jù)和工具的掌控力越來越靈活。運維人員收集原始數(shù)據(jù)后,經過數(shù)字孿生和可視化后,再進行打標、模型預訓練、結構化知識的提取,最終將專家的經驗和數(shù)據(jù)衍生為應用知識,進而實現(xiàn)工具的自動化和智能化升級,如圖2所示。
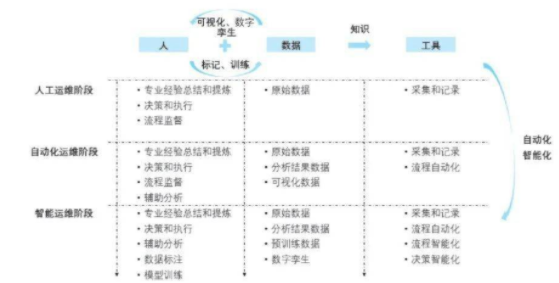
圖2.不同運維階段中人、數(shù)據(jù)、工具
3種角色功能和關系演化圖
2
實現(xiàn)智能運維的必要條件
無論是從已經進入AIOps階段的企業(yè)技術架構圖(如圖3所示)中,還是從Gartner的定義中,都可以清晰地看出:數(shù)據(jù)是智能運維的基礎。準確地說,具備數(shù)據(jù)能力是一家企業(yè)進入智能運維的必要條件。
根據(jù)Gartner的定義,AIOps產品或平臺主要包括以下5類技術要素。
•數(shù)據(jù)源:來自各IT基礎設施的底層記錄數(shù)據(jù)。
•大數(shù)據(jù)平臺:用于處理、分析靜態(tài)和動態(tài)實時數(shù)據(jù)。
•計算與分析:數(shù)據(jù)預處理、數(shù)據(jù)標準化等清洗工作。
•算法:用于計算和分析,以產生IT運維場景所需的結果。
•機器學習:包括無監(jiān)督、有監(jiān)督和半監(jiān)督學習。
數(shù)據(jù)是企業(yè)的核心資產,隨著數(shù)據(jù)量、數(shù)據(jù)維度的爆發(fā)式增長,現(xiàn)有的監(jiān)測分析工具在處理這類數(shù)據(jù)時壓力很大,且現(xiàn)有的BI或數(shù)據(jù)分析工具只能滿足簡單的數(shù)據(jù)分析和可視化功能,如Tableau其無法自動化地在企業(yè)跨越多種數(shù)據(jù)類型采集、洞察數(shù)據(jù),進而給出決策。
目前所有的AIOps平臺需能夠提取靜態(tài)數(shù)據(jù)(歷史數(shù)據(jù))和動態(tài)數(shù)據(jù)(實時、流式傳輸數(shù)據(jù))。這些平臺允許事件數(shù)據(jù)、用戶數(shù)據(jù)、日志數(shù)據(jù)以及圖形和文檔數(shù)據(jù)的提取、索引和存儲。
數(shù)據(jù)能力,具體包括數(shù)據(jù)采集、數(shù)據(jù)存儲、數(shù)據(jù)治理、數(shù)據(jù)服務4項核心能力,即以數(shù)據(jù)中臺/大數(shù)據(jù)平臺/數(shù)據(jù)湖等形式存在的數(shù)據(jù)底座,至于這幾種數(shù)據(jù)底座的名稱之間的細微差別,讀者可暫時理解為同一事物。
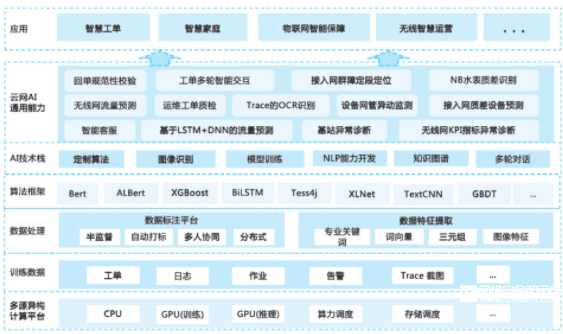
圖3.某企業(yè)AIOps技術架構圖
每天數(shù)據(jù)量在1TB以上、底層平臺超過5個以上的企業(yè),建立一個可用的數(shù)據(jù)底座至少需要3年時間。而且這3年中需要一邊建設數(shù)據(jù)底座一邊將其與運維業(yè)務緊密結合,在試錯中建設。構建統(tǒng)一監(jiān)控平臺,實現(xiàn)IT資源的統(tǒng)一管控。利用大數(shù)據(jù)的手段,采集、分析基礎設施、網絡、日志等IT監(jiān)控數(shù)據(jù),通過海量IT數(shù)據(jù)的實時處理分析,消除數(shù)據(jù)孤島,實現(xiàn)統(tǒng)一的告警,提升運維管理效率。
由于采集的數(shù)據(jù)集依然是按照業(yè)務邏輯從各平臺取出后按表存儲的,與后期各類運維場景使用的數(shù)據(jù)結構相差甚遠,因此,需要在數(shù)據(jù)底座上針對每種運維場景(當然場景的數(shù)量是慢慢積累的),建立企業(yè)自身運維的數(shù)據(jù)標準,并通過自動化程序和配置采集程序來采集標準數(shù)據(jù)。在數(shù)據(jù)底座上建立一個個標準化的數(shù)據(jù)模型,每種運維場景需要的數(shù)據(jù)可以是一個數(shù)據(jù)模型中的數(shù)據(jù),也可以是多個數(shù)據(jù)模型組合的數(shù)據(jù)?這種數(shù)據(jù)模型后期將在無人運維階段,通過數(shù)據(jù)孿生技術從大數(shù)據(jù)平臺中自動生成。數(shù)據(jù)將通過統(tǒng)一接口服務于智能運維。
3
智能運維未來發(fā)展趨勢
智能運維最終必然會進化為無人運維,類似汽車、飛機的無人駕駛,只有在人為需求變更條件下主動干預才會影響機器的正常決策。要想實現(xiàn)無人運維,背后一定需要類似人腦的“運維大腦”的實時支撐。
從圖4所示的基于無人運維技術體系架構來看,首先需要解決數(shù)據(jù)來源安全、分布式算力整合調度、人機智能融合、智能免疫系統(tǒng)、信任體系價值網絡和腦機操作接口等重大難題,進而實現(xiàn)主動任務求解、自適應強化學習、虛擬場景重建、認知整合、數(shù)據(jù)應用閉環(huán)統(tǒng)一和價值交互模式。
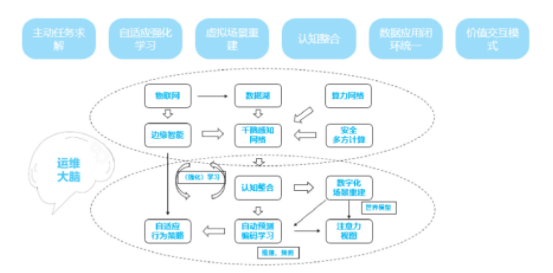
圖4.基于無人運維技術體系架構
要解決上述難題,實現(xiàn)“運維大腦”,提升其知識泛化能力,很可能是以區(qū)塊鏈技術建立分布式可信價值網絡生態(tài),加上聯(lián)邦學習,實現(xiàn)從數(shù)據(jù)提取、算法選擇、算力和存儲資源的使用,到數(shù)據(jù)在使用方的分析應用和優(yōu)化,在每一次反饋中不斷積累價值,形成知識。基于區(qū)塊鏈技術運維大腦數(shù)據(jù)計算流程示意圖如圖5所示。
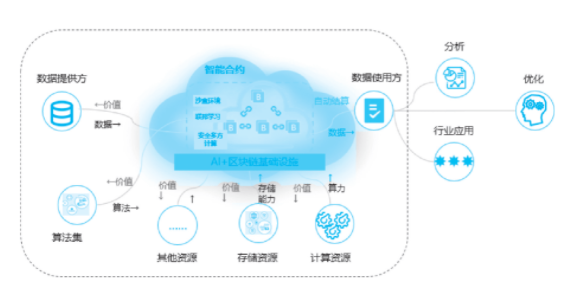
圖5.基于區(qū)塊鏈技術運維大腦數(shù)據(jù)計算流程示意圖
要實現(xiàn)上述目的,在可預見的未來至少需要以下核心技術
•數(shù)據(jù)聚合和價值交換:數(shù)據(jù)多方計算與隱私保護。
•數(shù)據(jù)的關聯(lián)與重構:數(shù)字孿生與注意力機制。
•千腦感知網絡:算力網絡、邊緣智能、分布式決策。
•認知整合:知識圖譜、基于場景的模仿學習。
•面向任務的自動機器學習(Auto-ML):自動超參優(yōu)化編碼學習、大規(guī)模圖卷積學習。
•認知智能混合技術:基于自動特征工程的認知特征提取、基于深度學習的視覺問答VQA(VisualQuestionAnswering)技術。
•基于強化學習的決策智能:基于圖的決策智能推理。
•數(shù)字化場景重建:基于GAN的視頻壓縮和重建。
•人機協(xié)同與腦機接口。
•安全免疫機制。
•多方協(xié)同智能:區(qū)塊鏈價值網絡。
實現(xiàn)“運維大腦”涉及的領域和基礎技術如下。
•大數(shù)據(jù)平臺。
•AI賦能平臺。
•區(qū)塊鏈數(shù)據(jù)多方計算。
•數(shù)字孿生技術。
•容器云平臺。
•圖數(shù)據(jù)庫引擎。
•大規(guī)模圖關聯(lián)模型。
•算力網絡。
•混合現(xiàn)實技術。
•自動機器學習。
•知識圖譜。
•價值網絡。
•自然語言處理。