根據(jù)我的觀察,大數(shù)據(jù)主要存在4大挑戰(zhàn):
- 大數(shù)據(jù)中的數(shù)據(jù)挑戰(zhàn)
- 大數(shù)據(jù)中的管理挑戰(zhàn)
- 大數(shù)據(jù)中的分析挑戰(zhàn)
- 大數(shù)據(jù)中的運(yùn)營(yíng)挑戰(zhàn)
一、大數(shù)據(jù)中的數(shù)據(jù)挑戰(zhàn)
大數(shù)據(jù)中的數(shù)據(jù)挑戰(zhàn)泛指處理數(shù)據(jù)時(shí)必須解決的問(wèn)題。哪里有大數(shù)據(jù),哪里就有大問(wèn)題。
當(dāng)您處理一層或另一層數(shù)據(jù)時(shí),您將需要一些特定的技能,讓我們深入了解它們。
1、數(shù)據(jù)存儲(chǔ)?
隨著存儲(chǔ)數(shù)據(jù)量的不斷增加,數(shù)據(jù)存儲(chǔ)問(wèn)題歷來(lái)是第一位的。這是任何處理數(shù)據(jù)的系統(tǒng)的基礎(chǔ)——有許多技術(shù)可以存儲(chǔ)大量原始數(shù)據(jù),這些數(shù)據(jù)來(lái)自傳統(tǒng)來(lái)源(如 OLTP 數(shù)據(jù)庫(kù))和更新的、結(jié)構(gòu)化程度較低的來(lái)源(如日志文件、傳感器、Web 分析、文檔檔案) 、媒體檔案等。正如你所看到的,這些是非常不同的領(lǐng)域,有自己的特點(diǎn),我們需要從所有這些領(lǐng)域收集數(shù)據(jù),以獲取有關(guān)整個(gè)系統(tǒng)的整體信息。
首先需要清楚使用哪種格式存儲(chǔ)數(shù)據(jù),如何優(yōu)化數(shù)據(jù)結(jié)構(gòu)以及如何優(yōu)化存儲(chǔ)數(shù)據(jù)。當(dāng)然,在這里,您可以想到在大數(shù)據(jù)世界中非常常見(jiàn)的Parquet、CSV、Avro 格式。此外,可以考慮使用 Bzip2、Snappy、Lzo 等編解碼器。好吧,優(yōu)化基本上要么是適當(dāng)?shù)姆謪^(qū),要么是做一些特定于存儲(chǔ)的事情。
使用Hadoop和HDFS構(gòu)建該層的主要技術(shù)之一。它因其耐用性和傳統(tǒng)設(shè)備上的無(wú)限規(guī)模而廣受歡迎。但是,如今,越來(lái)越多的數(shù)據(jù)存儲(chǔ)在云中,或者至少存儲(chǔ)在混合解決方案中——組織正在從過(guò)時(shí)的本地存儲(chǔ)系統(tǒng)轉(zhuǎn)移到托管服務(wù),例如 AWS S3、GCP GCS 或Azure Blobs。
對(duì)于 SQL 解決方案,流行的項(xiàng)目包括Hive、Apache Drill、Apache Impala、Apache Spark SQL和Presto。此外,還有更多有趣的數(shù)據(jù)倉(cāng)庫(kù)解決方案,我認(rèn)為它們位于簡(jiǎn)單的 SQL 引擎之上。稍后我們將討論它們。
對(duì)于 NoSQL 解決方案,它可以是支持 ACID的Cassandra 、用于文檔數(shù)據(jù)模型和可管理數(shù)據(jù)大小的MongoDB ,或者如果您在 AWS 云中,它可以用于可擴(kuò)展解決方案的AWS DynamoDB 。
對(duì)于圖形數(shù)據(jù)庫(kù),我只能回憶起Neo4j。它非常適合存儲(chǔ)圖形數(shù)據(jù)或相關(guān)信息,例如一群人及其關(guān)系。在傳統(tǒng)的 SQL 數(shù)據(jù)庫(kù)中對(duì)此類(lèi)信息進(jìn)行數(shù)據(jù)建模是一件痛苦的事情,而且效率非常低。
2、數(shù)據(jù)湖?
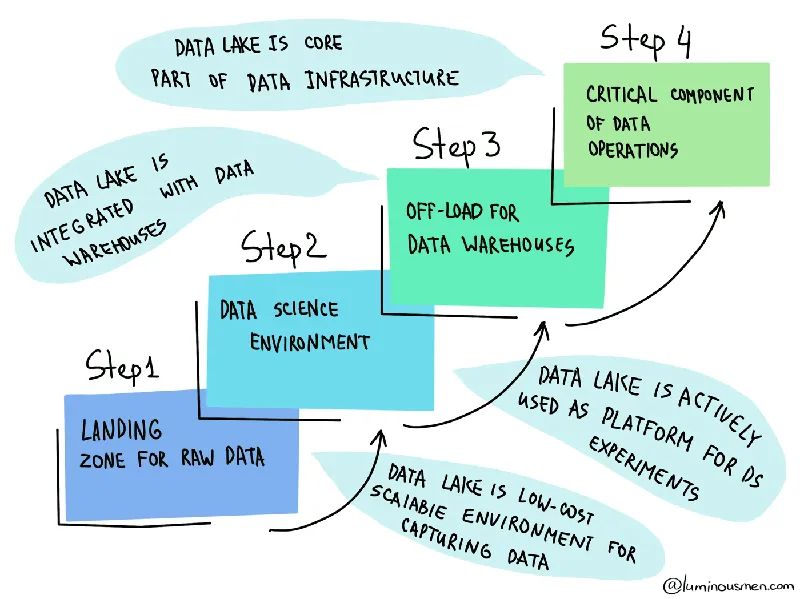
數(shù)據(jù)湖是企業(yè)數(shù)據(jù)的集中存儲(chǔ)庫(kù),允許存儲(chǔ)有關(guān)業(yè)務(wù)的所有結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)。在這里,我們按原樣存儲(chǔ)數(shù)據(jù),而不對(duì)其進(jìn)行結(jié)構(gòu)化,并在頂部運(yùn)行不同類(lèi)型的分析。
如今,數(shù)字化轉(zhuǎn)型實(shí)際上是將數(shù)據(jù)驅(qū)動(dòng)的方法應(yīng)用于業(yè)務(wù)的各個(gè)方面,以創(chuàng)造競(jìng)爭(zhēng)優(yōu)勢(shì)。這就是為什么越來(lái)越多的公司希望構(gòu)建自己的數(shù)據(jù)湖解決方案。這種趨勢(shì)仍在繼續(xù),并且仍然需要這些技能。
大多數(shù)情況下,Hadoop 發(fā)行版的供應(yīng)商選擇可能由客戶(hù)驅(qū)動(dòng),這取決于他們的個(gè)人偏好、供應(yīng)商的市場(chǎng)份額或現(xiàn)有的合作伙伴關(guān)系。用于本地集群的Hadoop分發(fā)供應(yīng)商是Cloudera、Hortonworks、Mapr和BigInsights。本地被認(rèn)為更安全。銀行、保險(xiǎn)公司和醫(yī)療機(jī)構(gòu)非常喜歡它,因?yàn)閿?shù)據(jù)不會(huì)離開(kāi)他們的場(chǎng)所。然而,在時(shí)間和精力方面,獲取和維護(hù)基礎(chǔ)設(shè)施將花費(fèi)更多。
還有來(lái)自 AWS、GCP 和 Azure 的云存儲(chǔ)解決方案。與本地解決方案相比,云解決方案在可擴(kuò)展性和即用型資源方面提供了更大的靈活性,但維護(hù)成本很高。
除此之外,還有一些數(shù)據(jù)平臺(tái)正在嘗試填補(bǔ)多個(gè)細(xì)分市場(chǎng)并創(chuàng)建集成解決方案,例如Apache Hudi、Delta Lake。
3、數(shù)據(jù)倉(cāng)庫(kù)

數(shù)據(jù)倉(cāng)庫(kù)可以描述為可用于分析和報(bào)告的有序數(shù)據(jù)存儲(chǔ)庫(kù),旨在針對(duì)聚合請(qǐng)求進(jìn)行優(yōu)化。在任何情況下,它都是構(gòu)建分析和數(shù)據(jù)驅(qū)動(dòng)決策的基礎(chǔ),就像 Data Lake 一樣,它們并不相互排斥,而是相互補(bǔ)充。
數(shù)據(jù)集市是數(shù)據(jù)倉(cāng)庫(kù)解決方案的最后一層,旨在滿足特定業(yè)務(wù)功能的要求。它們從不同來(lái)源提取數(shù)據(jù)并將其提供給業(yè)務(wù)用戶(hù)的能力使它們成為數(shù)據(jù)倉(cāng)庫(kù)領(lǐng)域的增長(zhǎng)趨勢(shì)。
趨勢(shì)數(shù)據(jù)倉(cāng)庫(kù)解決方案包括Teradata、Snowflake、BigQuery、AWS Redshift。
4、數(shù)據(jù)中心
有數(shù)據(jù)倉(cāng)庫(kù),其中信息被分類(lèi)、排序并以最終結(jié)論的形式呈現(xiàn)(其余的被丟棄),還有數(shù)據(jù)湖——“把所有東西都丟在這里,因?yàn)槟阌肋h(yuǎn)不知道什么會(huì)有用”。數(shù)據(jù)中心專(zhuān)注于不屬于第一類(lèi)或第二類(lèi)的人。
數(shù)據(jù)中心架構(gòu)允許您將數(shù)據(jù)留在原處,提供集中處理而不是存儲(chǔ)。數(shù)據(jù)在當(dāng)前所在的位置被搜索和訪問(wèn)。但是,由于數(shù)據(jù)中心是經(jīng)過(guò)規(guī)劃和管理的,因此組織必須投入大量時(shí)間和精力來(lái)確定其數(shù)據(jù)的含義、數(shù)據(jù)來(lái)源以及必須完成哪些轉(zhuǎn)換才能將其放入數(shù)據(jù)中心。
數(shù)據(jù)中心是一種不同的存儲(chǔ)架構(gòu)思考方式。我敢打賭,它在未來(lái)會(huì)引起一些關(guān)注——所有的支持部件今天都可用。
5、數(shù)據(jù)采集?
要?jiǎng)?chuàng)建數(shù)據(jù)存儲(chǔ),您需要將來(lái)自各種來(lái)源的數(shù)據(jù)采集到數(shù)據(jù)層中,無(wú)論是數(shù)據(jù)湖還是數(shù)據(jù)倉(cāng)庫(kù),或者只是 HDFS。數(shù)據(jù)源可以是諸如 Salesforce 之類(lèi)的 CRM、SAP 之類(lèi)的企業(yè)資源規(guī)劃系統(tǒng)、PostgreSQL 之類(lèi)的 RDBMS 或任何日志文件、文檔、社交網(wǎng)絡(luò)圖等系統(tǒng)。數(shù)據(jù)可以通過(guò)批處理作業(yè)或通過(guò)實(shí)時(shí)流上傳.
數(shù)據(jù)采集的工具有很多,最常見(jiàn)的一種是Sqoop。它提供了一個(gè)可擴(kuò)展的基于 Java 的框架,可用于開(kāi)發(fā)用于將數(shù)據(jù)導(dǎo)入 Hadoop 的驅(qū)動(dòng)程序。Sqoop 在 Hadoop 中的 MapReduce 框架上運(yùn)行,也可用于將數(shù)據(jù)從 Hadoop 導(dǎo)出到 RDBMS。
另一種常用工具是Flume。當(dāng)輸入數(shù)據(jù)流的速度比使用速度快時(shí)使用它。通常,F(xiàn)lume 用于采集 HDFS 或 Kafka 中的數(shù)據(jù)流,它可以充當(dāng) Kafka 生產(chǎn)者。多個(gè) Flume 代理也可用于將來(lái)自多個(gè)來(lái)源的數(shù)據(jù)收集到 Flume 收集器中。
另一個(gè)流行的工具是Nifi。Nifi 處理器是面向文件的,沒(méi)有模式。這意味著某些數(shù)據(jù)表示為 FlowFile(它可以是磁盤(pán)上的實(shí)際文件或在其他地方獲得的某些數(shù)據(jù)塊)。每個(gè)處理器負(fù)責(zé)了解數(shù)據(jù)內(nèi)容以使用它們。因此,如果一個(gè)處理器理解格式 A,而另一個(gè)處理器只理解格式 B,則您可能必須在兩個(gè)處理器之間轉(zhuǎn)換數(shù)據(jù)格式。
消息總線世界中事實(shí)上的標(biāo)準(zhǔn)之一是Kafka——一種開(kāi)源的流式消息傳遞總線,可以從您的數(shù)據(jù)源創(chuàng)建提要,對(duì)數(shù)據(jù)進(jìn)行分區(qū),并將其流式傳輸給消費(fèi)者。Apache Kafka 是一種成熟且強(qiáng)大的解決方案,可大規(guī)模用于生產(chǎn)。
6、數(shù)據(jù)處理?
根據(jù)數(shù)據(jù)采集管道,數(shù)據(jù)被傳輸?shù)綌?shù)據(jù)層。現(xiàn)在,您需要能夠處理大量數(shù)據(jù)的技術(shù)來(lái)促進(jìn)分析和處理這些數(shù)據(jù)。數(shù)據(jù)分析師和工程師希望針對(duì)需要巨大計(jì)算能力的大數(shù)據(jù)運(yùn)行查詢(xún)。數(shù)據(jù)處理層必須優(yōu)化數(shù)據(jù)以促進(jìn)高效分析,并提供計(jì)算引擎來(lái)執(zhí)行查詢(xún)。
計(jì)算機(jī)集群更適合滿足大數(shù)據(jù)管道的高計(jì)算需求。使用集群需要一個(gè)解決方案來(lái)管理集群成員、協(xié)調(diào)資源共享和調(diào)度工作節(jié)點(diǎn)上的實(shí)際工作。它可以由 Hadoop 的 YARN、Apache Mesos 或 Kubernetes 等軟件處理。
這一層最流行的模式是 ETL(Extract Transform Load)—— 一種流行的數(shù)據(jù)處理范式。本質(zhì)上,我們從源中提取數(shù)據(jù),對(duì)其進(jìn)行清理,并將其轉(zhuǎn)換為我們上傳到目標(biāo)數(shù)據(jù)庫(kù)、數(shù)據(jù)倉(cāng)庫(kù)或數(shù)據(jù)湖的結(jié)構(gòu)化信息。
成功實(shí)現(xiàn)此模式的工具之一是Apache Spark。這是最重要的大數(shù)據(jù)多功能工具之一,任何處理大量數(shù)據(jù)的人都應(yīng)該掌握它。它對(duì)大型集群上的結(jié)構(gòu)化或非結(jié)構(gòu)化數(shù)據(jù)執(zhí)行并行查詢(xún)和轉(zhuǎn)換。Spark 還提供了一個(gè) SQL 接口,并具有良好的流式處理和內(nèi)置的 ML 功能。
7、ETL 到 ELT?

目前,當(dāng)轉(zhuǎn)換發(fā)生在數(shù)據(jù)倉(cāng)庫(kù)內(nèi)部而不是預(yù)先進(jìn)行時(shí),從 ETL 到 ELT 的轉(zhuǎn)變。在我看來(lái),這是由于缺乏對(duì)數(shù)據(jù)的了解,因?yàn)閭鹘y(tǒng)上對(duì)于必須進(jìn)入數(shù)據(jù)倉(cāng)庫(kù)以使其穩(wěn)定并可供用戶(hù)訪問(wèn)的內(nèi)容有很多計(jì)劃和嚴(yán)格要求。然后是輸入數(shù)據(jù)格式、輸出結(jié)構(gòu)格式等的變化。
Snowflake、AWS Redshift等工具允許在加載的數(shù)據(jù)(甚至是非結(jié)構(gòu)化數(shù)據(jù))上創(chuàng)建一個(gè)抽象層,從而在數(shù)據(jù)上提供一個(gè)簡(jiǎn)單的 SQL API,而無(wú)需考慮字母 T。另一個(gè)支持所有 SQL 相關(guān)工作流的工具是dbt。
8、批量到實(shí)時(shí)?
現(xiàn)在很明顯,實(shí)時(shí)數(shù)據(jù)收集系統(tǒng)正在迅速取代批量 ETL,使流數(shù)據(jù)成為現(xiàn)實(shí)。越來(lái)越多的攝取和處理層都轉(zhuǎn)向?qū)崟r(shí),這反過(guò)來(lái)又促使我們學(xué)習(xí)新概念,使用可以進(jìn)行批處理和實(shí)時(shí)處理的多功能工具,例如Spark和Flink。
9、內(nèi)存數(shù)據(jù)計(jì)算?
由于內(nèi)存變得更便宜并且企業(yè)依賴(lài)于實(shí)時(shí)結(jié)果,內(nèi)存計(jì)算使他們能夠擁有更豐富、更具交互性的儀表板,這些儀表板可提供最新數(shù)據(jù)并幾乎可以立即進(jìn)行報(bào)告。通過(guò)分析內(nèi)存而不是硬盤(pán)驅(qū)動(dòng)器中的數(shù)據(jù),他們可以即時(shí)查看數(shù)據(jù)并迅速采取行動(dòng)。
在大多數(shù)情況下,所有已知的解決方案都已經(jīng)使用或嘗試使用這種方法。同樣,最容易理解的例子是Spark和Apache Ignite等數(shù)據(jù)網(wǎng)格的實(shí)現(xiàn)。
Apache Arrow將列式數(shù)據(jù)結(jié)構(gòu)的優(yōu)勢(shì)與內(nèi)存計(jì)算相結(jié)合。它提供了這些現(xiàn)代技術(shù)的性能優(yōu)勢(shì),同時(shí)還提供了復(fù)雜數(shù)據(jù)和動(dòng)態(tài)模式的靈活性。我實(shí)際上不知道任何其他這樣的格式。
二、大數(shù)據(jù)中的管理挑戰(zhàn)
另一個(gè)知識(shí)領(lǐng)域,基本上位于稍微不同的平面上,但與數(shù)據(jù)直接相關(guān)。管理挑戰(zhàn)涉及隱私、安全、治理和數(shù)據(jù)/元數(shù)據(jù)管理。
1、數(shù)據(jù)檢索?
數(shù)據(jù)檢索系統(tǒng)是一個(gè)算法網(wǎng)絡(luò),有助于根據(jù)用戶(hù)需求搜索相關(guān)數(shù)據(jù)/文檔。
為了對(duì)大量數(shù)據(jù)執(zhí)行有效的搜索,不建議執(zhí)行簡(jiǎn)單的掃描 - 然后會(huì)出現(xiàn)各種工具和解決方案。我看到的最常見(jiàn)的工具之一是ElasticSearch。它用于互聯(lián)網(wǎng)搜索、日志分析和大數(shù)據(jù)分析。ElasticSearch 更受歡迎,因?yàn)樗子诎惭b,無(wú)需任何額外軟件即可擴(kuò)展到數(shù)百個(gè)節(jié)點(diǎn),并且由于其內(nèi)置的 REST API 易于使用。
此外,著名的工具還有Solr、Sphinx和Lucene。
2、數(shù)據(jù)治理?
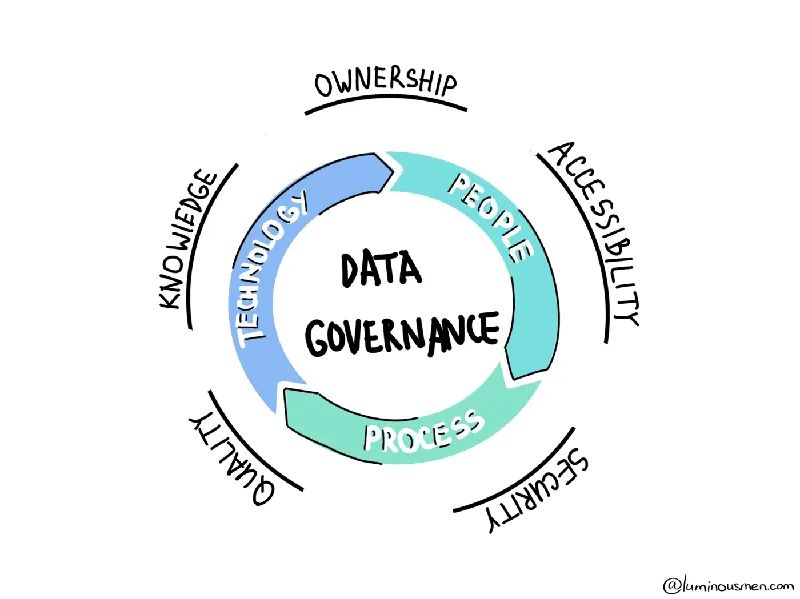
數(shù)據(jù)治理是一種總稱(chēng),用于表示“我想控制我的數(shù)據(jù)”。這可能是大數(shù)據(jù)的重要領(lǐng)域之一,在我看來(lái)仍然被低估并且沒(méi)有好的解決方案。數(shù)據(jù)治理的目標(biāo)是建立標(biāo)準(zhǔn)化、集成、保護(hù)和存儲(chǔ)數(shù)據(jù)的方法、職責(zé)和流程。如果沒(méi)有有效的數(shù)據(jù)治理,組織不同系統(tǒng)中的數(shù)據(jù)不一致將無(wú)法消除。這會(huì)使數(shù)據(jù)集成復(fù)雜化,并產(chǎn)生影響商業(yè)智能、企業(yè)報(bào)告和分析應(yīng)用程序準(zhǔn)確性的數(shù)據(jù)完整性問(wèn)題。
我當(dāng)然不是這個(gè)領(lǐng)域的專(zhuān)家,但我在這里看到的工具是Informatica、Talend、Semarchy。
3、數(shù)據(jù)安全?
由于數(shù)據(jù)保護(hù)水平跟不上數(shù)據(jù)、供應(yīng)商和人員的增長(zhǎng),不斷增加的數(shù)據(jù)量給他們的入侵、泄漏和網(wǎng)絡(luò)攻擊防護(hù)帶來(lái)了額外的挑戰(zhàn)。全面的端到端保護(hù)不僅涉及在數(shù)據(jù)的整個(gè)生命周期(靜態(tài)和傳輸中)加密數(shù)據(jù),還包括從項(xiàng)目一開(kāi)始就對(duì)其進(jìn)行保護(hù)。正如您所看到的,這會(huì)影響我們?cè)诒疚闹杏懻摰乃蟹矫妫⑶揖拖裼嘘P(guān)信息安全的所有內(nèi)容一樣,很難做到正確。
GDPR、CCPA、LGPD 等隱私法的出現(xiàn)對(duì)不合規(guī)造成了嚴(yán)重后果。企業(yè)必須考慮數(shù)據(jù)的機(jī)密性。這些領(lǐng)域的專(zhuān)家的存在成為必要。
4、數(shù)據(jù)目錄?
通常,在公司內(nèi)部,我們擁有大量不同形式、存儲(chǔ)方式、格式的數(shù)據(jù),并具有不同程度的訪問(wèn)權(quán)限。要查找數(shù)據(jù),您需要確切地知道在哪里找到它或知道從哪里開(kāi)始查找(如果有這樣的地方)。這就是所謂的數(shù)據(jù)目錄或數(shù)據(jù)目錄發(fā)揮作用的地方。
公司數(shù)據(jù)源的管理是一個(gè)基本過(guò)程,它基于公司內(nèi)各種有限群體已知的信息。但是,收集有關(guān)存儲(chǔ)在組織內(nèi)部的數(shù)據(jù)的所有元數(shù)據(jù)并進(jìn)行管理并不容易——人們來(lái)來(lái)去去,數(shù)據(jù)被刪除和添加。因此,構(gòu)建數(shù)據(jù)目錄是一項(xiàng)重要但復(fù)雜的任務(wù)。
三、大數(shù)據(jù)中的分析挑戰(zhàn)
分析和商業(yè)智能是一種用于制定數(shù)據(jù)驅(qū)動(dòng)決策并提供可以幫助企業(yè)的信息的方法。使用此級(jí)別的技術(shù),您可以啟動(dòng)查詢(xún)以回答企業(yè)提出的問(wèn)題、切片數(shù)據(jù)、構(gòu)建儀表板并創(chuàng)建清晰的可視化。
有了更多數(shù)據(jù),您就可以做出更準(zhǔn)確的預(yù)測(cè)和更可靠的解決方案,并構(gòu)建新的解決方案,在 ML 階梯上越爬越高。
1、機(jī)器學(xué)習(xí)?
機(jī)器學(xué)習(xí),一種特定的分析方法,允許您創(chuàng)建可以分析大型復(fù)雜數(shù)據(jù)并做出預(yù)測(cè)或決策的模型,而無(wú)需明確編程。越來(lái)越多的組織使用 ML 方法來(lái)補(bǔ)充他們的日常運(yùn)營(yíng)分析和正常的業(yè)務(wù)運(yùn)營(yíng)。
過(guò)去,ML 在一定程度上受到數(shù)據(jù)科學(xué)家無(wú)法在數(shù)據(jù)工程師團(tuán)隊(duì)將解決方案部署到生產(chǎn)環(huán)境之前對(duì)其進(jìn)行評(píng)估和測(cè)試這一事實(shí)的限制。事實(shí)上,大多數(shù)組織都有一個(gè)傳統(tǒng)的 BI/分析團(tuán)隊(duì),其次是獨(dú)立的數(shù)據(jù)科學(xué)團(tuán)隊(duì)和數(shù)據(jù)工程師團(tuán)隊(duì)。這些技能組合現(xiàn)在已經(jīng)開(kāi)始重疊,隨著大數(shù)據(jù)緩慢地向分析和構(gòu)建基于大數(shù)據(jù)的知識(shí),這些團(tuán)隊(duì)更加周到地合作。因?yàn)闆](méi)有機(jī)器學(xué)習(xí)的幫助,大數(shù)據(jù)太大了。因此,至少需要理解我認(rèn)為的 ML 的基本概念。當(dāng)然,應(yīng)該特別注意它所依賴(lài)的東西,如統(tǒng)計(jì)、ML 方法優(yōu)化方法、偏差/方差、要理解的不同指標(biāo)(這實(shí)際上很重要)等。在應(yīng)用機(jī)器學(xué)習(xí)中,你需要了解為什么一切正常,公式并不重要,但通常,那些不懂模型背后的語(yǔ)言的人會(huì)犯非常愚蠢的錯(cuò)誤。
還有很多要說(shuō)的,我下次再說(shuō)。ML 里面有很多領(lǐng)域——NLP、CV、推薦系統(tǒng)、知識(shí)表示等,但是通常,當(dāng)你至少理解了開(kāi)始時(shí),你已經(jīng)理解了你不理解的東西,所以當(dāng)然,你可以盡可能深入想。
如果您想成為一名機(jī)器學(xué)習(xí)工程師,請(qǐng)確保您了解Python。這是機(jī)器學(xué)習(xí)的通用語(yǔ)。然后值得學(xué)習(xí)了解用于處理數(shù)據(jù)的不同類(lèi)型的框架,例如NumPy、Pandas、Dask和已經(jīng)提到的Apache Spark。當(dāng)然,還有最流行的 ML 庫(kù):Scikit-Learn和XGBoost。
我認(rèn)為每個(gè)人都明白,ML 中真正重要的方向長(zhǎng)期以來(lái)一直與深度學(xué)習(xí)相關(guān)。經(jīng)典算法當(dāng)然不會(huì)去任何地方。在大多數(shù)情況下,它們足以制作一個(gè)好的模型,但未來(lái)當(dāng)然在于神經(jīng)網(wǎng)絡(luò)。深度學(xué)習(xí)的魔力在于它會(huì)隨著更多的數(shù)據(jù)而變得更好。另外,值得一提的是,可以在此處添加遷移學(xué)習(xí)、1cycle 策略、Cuda 和 GPU 優(yōu)化等詞。
2、分布式機(jī)器學(xué)習(xí)
另一件值得一提的是分布式機(jī)器學(xué)習(xí)。正如我所說(shuō),大數(shù)據(jù)正在慢慢走向更復(fù)雜的大數(shù)據(jù)分析。存儲(chǔ)在中央存儲(chǔ)庫(kù)中的大型數(shù)據(jù)集需要巨大的處理和計(jì)算需求,因此分布式 ML 是正確的方向,盡管它存在很多問(wèn)題。
我個(gè)人對(duì)這種方法很感興趣,但除了大公司之外,它對(duì)任何人都無(wú)關(guān)緊要。模型的準(zhǔn)確性對(duì)他們來(lái)說(shuō)非常重要,這只能通過(guò)創(chuàng)建具有數(shù)百萬(wàn)個(gè)參數(shù)和大量數(shù)據(jù)的巨大模型來(lái)獲得。對(duì)于所有其他人,正如我所說(shuō),關(guān)于子集或預(yù)聚合數(shù)據(jù)的經(jīng)典算法非常適合實(shí)際應(yīng)用。
3、實(shí)時(shí)分析
雖然組織通常重視實(shí)時(shí)數(shù)據(jù)管理,但并非所有公司都對(duì)大數(shù)據(jù)進(jìn)行實(shí)時(shí)分析。原因可能會(huì)有所不同——缺乏經(jīng)驗(yàn)或資金不足、擔(dān)心相關(guān)問(wèn)題或管理層普遍不愿。然而,那些實(shí)施實(shí)時(shí)分析的公司將獲得競(jìng)爭(zhēng)優(yōu)勢(shì)。
這里的工具是Apache Spark Streaming、Apache Ignite Streaming、Apache Flink、AWS Kinesis。
4、數(shù)據(jù)科學(xué)自動(dòng)化
為了以某種方式自動(dòng)化數(shù)據(jù)預(yù)處理、特征工程、模型選擇和配置以及結(jié)果評(píng)估,發(fā)明了 AutoML。AutoML 可以自動(dòng)執(zhí)行這些任務(wù),并且可以了解在哪里繼續(xù)研究。
當(dāng)然,這聽(tīng)起來(lái)很棒,但它的效果如何?這個(gè)問(wèn)題的答案取決于你如何使用它。這是關(guān)于了解人們擅長(zhǎng)的領(lǐng)域以及機(jī)器擅長(zhǎng)的領(lǐng)域。人們善于將現(xiàn)有數(shù)據(jù)與現(xiàn)實(shí)世界聯(lián)系起來(lái)——他們了解業(yè)務(wù)領(lǐng)域,他們了解特定數(shù)據(jù)的含義。機(jī)器擅長(zhǎng)計(jì)算統(tǒng)計(jì)數(shù)據(jù)、存儲(chǔ)和更新?tīng)顟B(tài),以及做重復(fù)的過(guò)程。探索性數(shù)據(jù)分析、數(shù)據(jù)預(yù)處理、超參數(shù)調(diào)整、模型選擇和將模型投入生產(chǎn)等任務(wù)可以通過(guò)自動(dòng)化機(jī)器學(xué)習(xí)框架在一定程度上自動(dòng)化,但良好的特征工程和得出可操作的見(jiàn)解可以通過(guò)人類(lèi)數(shù)據(jù)來(lái)完成了解商業(yè)環(huán)境的科學(xué)家。通過(guò)分離這些活動(dòng),我們現(xiàn)在可以輕松地從 AutoML 中受益,
5、可視化和商業(yè)智能?
由于大數(shù)據(jù)系統(tǒng)中處理的信息類(lèi)型,識(shí)別數(shù)據(jù)隨時(shí)間的趨勢(shì)或變化通常比值本身更重要。數(shù)據(jù)可視化是理解大量數(shù)據(jù)點(diǎn)的最有用的方法之一。它通過(guò)以易于理解的形式引導(dǎo)數(shù)據(jù)、突出趨勢(shì)和偏差來(lái)幫助講述故事。
通過(guò) BI 將來(lái)自各種來(lái)源的未處理信息轉(zhuǎn)換為方便且易于理解的分析。BI 系統(tǒng)可以應(yīng)用于任何行業(yè)或活動(dòng)領(lǐng)域——在公司整體層面以及部門(mén)或單個(gè)產(chǎn)品層面。
最流行的可視化和 BI 工具,在我看來(lái),除了上面描述的所有其他技術(shù)堆棧之外,還有Tableau、Looker、Microsoft Power BI、Qlik 。
Tableau 是一款功能強(qiáng)大的表格 BI 和數(shù)據(jù)可視化工具,可連接到數(shù)據(jù)并允許您執(zhí)行詳細(xì)、全面的分析以及繪制圖表和儀表板。
Looker 是一個(gè)基于云的 BI 平臺(tái),允許您在配置講述數(shù)據(jù)故事的可視化后,使用 SQL 定義的指標(biāo)查詢(xún)和分析大量數(shù)據(jù)。
另一種常用于數(shù)據(jù)交互工作的可視化技術(shù)是“筆記本”。它們?cè)试S以促進(jìn)共享、演示或協(xié)作的格式進(jìn)行交互式研究和數(shù)據(jù)可視化。這種可視化界面的流行示例是Jupyter notebook、Apache Zeppelin和Polynote。
四、大數(shù)據(jù)中的運(yùn)營(yíng)挑戰(zhàn)
要解決其他帖子中描述的所有挑戰(zhàn),您需要一個(gè)具有正確架構(gòu)的基礎(chǔ)架構(gòu)以及該基礎(chǔ)架構(gòu)的正確管理、監(jiān)控和供應(yīng)環(huán)境。這不是我在本節(jié)中包含的全部?jī)?nèi)容——還包括管道編排和在數(shù)據(jù)管理的各個(gè)領(lǐng)域引入 DevOps 實(shí)踐。
1、微服務(wù)管理
微服務(wù)的建設(shè)早已成為一個(gè)解決的問(wèn)題。一種或另一種方式,所有嚴(yán)肅的解決方案都建立在微服務(wù)架構(gòu)上。這里有Docker容器、Kubernetes、Helm、Terraform、Vault、Consul以及它周?chē)囊磺小_@一切都成為了一個(gè)標(biāo)準(zhǔn)而沒(méi)有被注意到。
2、監(jiān)控?
實(shí)時(shí)數(shù)據(jù)通常用于可視化應(yīng)用程序和服務(wù)器指標(biāo)。數(shù)據(jù)經(jīng)常更改,指標(biāo)中的大增量往往表明對(duì)系統(tǒng)或組織的健康狀況產(chǎn)生重大影響。在這些情況下,Prometheus等項(xiàng)目可用于處理數(shù)據(jù)流和時(shí)間序列數(shù)據(jù)可視化。
3、日志管理?
日志管理是處理由不同軟件應(yīng)用程序及其運(yùn)行的基礎(chǔ)設(shè)施生成的日志事件的過(guò)程。它可以包括日志的收集、分析、存儲(chǔ)和搜索,最終目標(biāo)是使用數(shù)據(jù)進(jìn)行故障排除和獲取業(yè)務(wù)、應(yīng)用程序和基礎(chǔ)架構(gòu)信息。
這里的重要工具之一是ELK,它由以下組件組成——Elasticsearch(文本搜索工具)、Logstash 和 Beats(數(shù)據(jù)發(fā)送工具)和 Kibana(數(shù)據(jù)可視化工具)。它們共同為實(shí)時(shí)數(shù)據(jù)分析提供了一個(gè)完整的工作工具。雖然它們都旨在協(xié)同工作,但它們每個(gè)都是一個(gè)單獨(dú)的項(xiàng)目。ELK 提供了報(bào)表創(chuàng)建、告警、日志搜索等在線分析功能。這使得它不僅是 DevOps 的通用工具,也是上述領(lǐng)域的通用工具。
另一種工具Splunk是一種機(jī)器數(shù)據(jù)工具,它使用戶(hù)、管理員和開(kāi)發(fā)人員能夠立即接收和分析由應(yīng)用程序、IT 基礎(chǔ)設(shè)施中的網(wǎng)絡(luò)設(shè)備以及任何其他機(jī)器數(shù)據(jù)創(chuàng)建的所有數(shù)據(jù)。Splunk 可以通過(guò)圖表、警報(bào)、報(bào)告等方式提供實(shí)時(shí)信息,從而接收機(jī)器數(shù)據(jù)并將其轉(zhuǎn)化為實(shí)時(shí)分析。
4、管道編排?
大多數(shù)大數(shù)據(jù)解決方案都包含封裝在工作流中的重復(fù)數(shù)據(jù)處理操作。管道編排工具有助于自動(dòng)化這些工作流程。他們可以以容錯(cuò)的方式計(jì)劃作業(yè)、執(zhí)行工作流和協(xié)調(diào)任務(wù)之間的依賴(lài)關(guān)系。
我以前聽(tīng)過(guò) Oozie,現(xiàn)在主要是Airflow、Dagster、Prefect或AWS Step Functions。
5、云
在大數(shù)據(jù)中,很明顯,未來(lái)在于云,任何對(duì)數(shù)據(jù)管理感興趣的人都最好了解它的概念。除了在云級(jí)別應(yīng)用的編程模式(Gateway API、Pub/Sub、Sidecars 等)之外,您還會(huì)遇到不同的概念,例如基礎(chǔ)架構(gòu)即代碼、無(wú)服務(wù)器,當(dāng)然還有架構(gòu)概念(N 層、微服務(wù)、松散耦合等)。就個(gè)人而言,它讓我對(duì)更高層次的工程方法原理有了更深入的理解,并(一點(diǎn))提升了架構(gòu)方法。有GCP、AWS和Azure等云。我想沒(méi)有人會(huì)爭(zhēng)辯說(shuō)沒(méi)有其他選擇。例如,您決定選擇 AWS,但所有云的設(shè)計(jì)方式都相同,盡管它們都有自己的特點(diǎn),而且并非所有 CSP 服務(wù)都相互匹配。
6、數(shù)據(jù)/解決方案遷移?
從本地解決方案到云的數(shù)據(jù)遷移的集成和準(zhǔn)備過(guò)程既復(fù)雜又耗時(shí)。除了遷移大量現(xiàn)有數(shù)據(jù)外,公司還必須在遷移完成前的幾周或幾個(gè)月內(nèi)同步其數(shù)據(jù)源和平臺(tái)。除了遷移之外,企業(yè)正在準(zhǔn)備災(zāi)難恢復(fù)計(jì)劃,以便在不犧牲業(yè)務(wù)的情況下為任何事情做好準(zhǔn)備,這里顯而易見(jiàn)的解決方案也是遷移到云。
7、MLOps?
我們的機(jī)器學(xué)習(xí)算法很好,但要取得好的結(jié)果確實(shí)需要一個(gè)由數(shù)據(jù)專(zhuān)家、數(shù)據(jù)工程師、現(xiàn)場(chǎng)專(zhuān)家和更多支持人員組成的龐大團(tuán)隊(duì)。雖然專(zhuān)家的成本不夠約束,但我們的理解仍然很原始。最后,將模型投入生產(chǎn)并使其保持最新是最后一個(gè)障礙,因?yàn)槟P蛣?chuàng)建的結(jié)果通常只能通過(guò)使用相同的用于學(xué)習(xí)的昂貴且復(fù)雜的架構(gòu)來(lái)實(shí)現(xiàn)。應(yīng)該理解,轉(zhuǎn)向生產(chǎn)是一個(gè)過(guò)程,而不是一個(gè)步驟,它在模型開(kāi)發(fā)之前很久就開(kāi)始了。它的第一步是定義業(yè)務(wù)目標(biāo)、可以從數(shù)據(jù)中提取的價(jià)值假設(shè)以及應(yīng)用的業(yè)務(wù)理念。
MLOps 是技術(shù)和 ML 流程以及在業(yè)務(wù)流程中實(shí)施已開(kāi)發(fā)模型的方法的組合。這個(gè)概念是作為與 ML 模型和 ML 方法相關(guān)的 DevOps 的類(lèi)比而出現(xiàn)的。通常,MLOps 系統(tǒng)包括用于收集和聚合數(shù)據(jù)、分析和準(zhǔn)備用于 ML 建模的平臺(tái)、用于執(zhí)行計(jì)算和分析的工具,以及用于在不同生命周期過(guò)程之間自動(dòng)傳輸 ML 模型、數(shù)據(jù)和衍生軟件產(chǎn)品的工具。這種統(tǒng)一的管道部分或完全自動(dòng)化了數(shù)據(jù)科學(xué)家、數(shù)據(jù)工程師、ML 工程師或大數(shù)據(jù)開(kāi)發(fā)人員的工作任務(wù)。
我認(rèn)為以下是最流行的 MLOps 工具:
- AWS SageMaker是一個(gè)基于云的機(jī)器學(xué)習(xí)平臺(tái),允許開(kāi)發(fā)人員在 AWS 云中創(chuàng)建、訓(xùn)練和部署 ML 模型;
- Google 的Kubeflow for Kubernetes 是一個(gè)免費(fèi)的開(kāi)源機(jī)器學(xué)習(xí)平臺(tái),用于在 Kubernetes 容器虛擬化環(huán)境中使用機(jī)器學(xué)習(xí)管道;
- MLFlow是一個(gè)開(kāi)源平臺(tái),用于管理機(jī)器學(xué)習(xí)的生命周期,包括實(shí)驗(yàn)、復(fù)制、部署和 ML 模型的中央注冊(cè)表;
- Sacred是一個(gè)用于自動(dòng)化 ML 實(shí)驗(yàn)的工具,從跟蹤參數(shù)到保存配置和再現(xiàn)結(jié)果;
- DVC是一個(gè)類(lèi)似于 Git 的開(kāi)源版本控制系統(tǒng),用于本地使用的 ML 項(xiàng)目。
除此之外,還有很多工具可以將 ML 模型投入生產(chǎn),除了已經(jīng)說(shuō)過(guò)的之外,最受歡迎的工具我認(rèn)為是TensorFlow Serving和Vowpal Wabbit。
結(jié)論
結(jié)果很多,似乎我什么也沒(méi)說(shuō)。另請(qǐng)查看Tobias Macey 對(duì) 2021 年數(shù)據(jù)工程前景的采訪。
可用的產(chǎn)品太多。他們中的大多數(shù)聲稱(chēng)可以解決您公司遇到的所有數(shù)據(jù)問(wèn)題。但事實(shí)并非如此。
我不認(rèn)為自己是所有方面的專(zhuān)家,只是在這里推測(cè)技術(shù)。但正如您從我的文章中所看到的那樣,許多技能在大數(shù)據(jù)的幾個(gè)領(lǐng)域重疊,并不止于此。有了他們,你就不會(huì)害怕找不到工作。
不要追逐趨勢(shì)——培養(yǎng)與時(shí)俱進(jìn)的技能。最相關(guān)的技能可能是軟技能。
與大量數(shù)據(jù)工程活動(dòng)相關(guān)的陡峭學(xué)習(xí)曲線變成了懸崖。開(kāi)發(fā)人員的手工編碼項(xiàng)目需要對(duì)組織的許多方面以及大量工具和現(xiàn)有解決方案有深入的了解。
在數(shù)據(jù)管理方面,我們?nèi)匀惶幱诳褚暗奈鞑浚绕涫窃?ML ...